Xarray with Dask Arrays
Contents
Live Notebook
You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.
Xarray with Dask Arrays¶
![]()
Xarray is an open source project and Python package that extends the labeled data functionality of Pandas to N-dimensional array-like datasets. It shares a similar API to NumPy and Pandas and supports both Dask and NumPy arrays under the hood.
[1]:
%matplotlib inline
from dask.distributed import Client
import xarray as xr
Start Dask Client for Dashboard¶
Starting the Dask Client is optional. It will provide a dashboard which is useful to gain insight on the computation.
The link to the dashboard will become visible when you create the client below. We recommend having it open on one side of your screen while using your notebook on the other side. This can take some effort to arrange your windows, but seeing them both at the same is very useful when learning.
[2]:
client = Client(n_workers=2, threads_per_worker=2, memory_limit='1GB')
client
[2]:
Client
Client-4eea680b-0de0-11ed-9d1a-000d3a8f7959
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
8c9bb588
| Dashboard: http://127.0.0.1:8787/status | Workers: 2 |
| Total threads: 4 | Total memory: 1.86 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-f26c7784-2ac7-471c-91ac-1b0f9e3135b1
| Comm: tcp://127.0.0.1:36327 | Workers: 2 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 4 |
| Started: Just now | Total memory: 1.86 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:34819 | Total threads: 2 |
| Dashboard: http://127.0.0.1:39963/status | Memory: 0.93 GiB |
| Nanny: tcp://127.0.0.1:38683 | |
| Local directory: /home/runner/work/dask-examples/dask-examples/dask-worker-space/worker-kg42o2xu | |
Worker: 1
| Comm: tcp://127.0.0.1:39355 | Total threads: 2 |
| Dashboard: http://127.0.0.1:43051/status | Memory: 0.93 GiB |
| Nanny: tcp://127.0.0.1:43647 | |
| Local directory: /home/runner/work/dask-examples/dask-examples/dask-worker-space/worker-q4dslyjg | |
Open a sample dataset¶
We will use some of xarray’s tutorial data for this example. By specifying the chunk shape, xarray will automatically create Dask arrays for each data variable in the Dataset. In xarray, Datasets are dict-like container of labeled arrays, analogous to the pandas.DataFrame. Note that we’re taking advantage of xarray’s dimension labels when specifying chunk shapes.
[3]:
ds = xr.tutorial.open_dataset('air_temperature',
chunks={'lat': 25, 'lon': 25, 'time': -1})
ds
[3]:
<xarray.Dataset>
Dimensions: (lat: 25, time: 2920, lon: 53)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 dask.array<chunksize=(2920, 25, 25), meta=np.ndarray>
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...Quickly inspecting the Dataset above, we’ll note that this Dataset has three dimensions akin to axes in NumPy (lat, lon, and time), three coordinate variables akin to pandas.Index objects (also named lat, lon, and time), and one data variable (air). Xarray also holds Dataset specific metadata as attributes.
[4]:
da = ds['air']
da
[4]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
dask.array<open_dataset-ced301335a37488ca2d3a9447fa27157air, shape=(2920, 25, 53), dtype=float32, chunksize=(2920, 25, 25), chunktype=numpy.ndarray>
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]Each data variable in xarray is called a DataArray. These are the fundamental labeled array objects in xarray. Much like the Dataset, DataArrays also have dimensions and coordinates that support many of its label-based opperations.
[5]:
da.data
[5]:
|
Accessing the underlying array of data is done via the data property. Here we can see that we have a Dask array. If this array were to be backed by a NumPy array, this property would point to the actual values in the array.
Use Standard Xarray Operations¶
In almost all cases, operations using xarray objects are identical, regardless if the underlying data is stored as a Dask array or a NumPy array.
[6]:
da2 = da.groupby('time.month').mean('time')
da3 = da - da2
da3
[6]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53, month: 12)> dask.array<sub, shape=(2920, 25, 53, 12), dtype=float32, chunksize=(2920, 25, 25, 1), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 * month (month) int64 1 2 3 4 5 6 7 8 9 10 11 12
Call .compute() or .load() when you want your result as a xarray.DataArray with data stored as NumPy arrays.
If you started Client() above then you may want to watch the status page during computation.
[7]:
computed_da = da3.load()
type(computed_da.data)
[7]:
numpy.ndarray
[8]:
computed_da
[8]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53, month: 12)>
array([[[[-5.14987183e+00, -5.47715759e+00, -9.83168030e+00, ...,
-2.06136017e+01, -1.25448456e+01, -6.77099609e+00],
[-3.88607788e+00, -3.90576172e+00, -8.17987061e+00, ...,
-1.87125549e+01, -1.11448669e+01, -5.52117920e+00],
[-2.71517944e+00, -2.44839478e+00, -6.68945312e+00, ...,
-1.70036011e+01, -9.99716187e+00, -4.41302490e+00],
...,
[-1.02611389e+01, -9.05839539e+00, -9.39399719e+00, ...,
-1.53933716e+01, -1.01606750e+01, -6.97190857e+00],
[-8.58795166e+00, -7.50210571e+00, -7.61483765e+00, ...,
-1.35699463e+01, -8.43449402e+00, -5.52383423e+00],
[-7.04670715e+00, -5.84384155e+00, -5.70956421e+00, ...,
-1.18162537e+01, -6.54209900e+00, -4.02824402e+00]],
[[-5.05761719e+00, -4.00010681e+00, -9.17195129e+00, ...,
-2.52222595e+01, -1.53296814e+01, -5.93362427e+00],
[-4.40733337e+00, -3.25991821e+00, -8.36616516e+00, ...,
-2.44294434e+01, -1.41292725e+01, -5.66036987e+00],
[-4.01040649e+00, -2.77757263e+00, -7.87347412e+00, ...,
-2.40147858e+01, -1.34914398e+01, -5.78581238e+00],
...
-3.56890869e+00, -2.47412109e+00, -1.16558838e+00],
[ 6.08795166e-01, 1.47219849e+00, 1.11965942e+00, ...,
-3.59872437e+00, -2.50396729e+00, -1.15667725e+00],
[ 6.59942627e-01, 1.48742676e+00, 1.03787231e+00, ...,
-3.84628296e+00, -2.71829224e+00, -1.33132935e+00]],
[[ 5.35827637e-01, 4.01092529e-01, 3.08258057e-01, ...,
-1.68054199e+00, -1.12142944e+00, -1.90887451e-01],
[ 8.51684570e-01, 8.73504639e-01, 6.26892090e-01, ...,
-1.33462524e+00, -7.66601562e-01, 1.03210449e-01],
[ 1.04107666e+00, 1.23202515e+00, 8.63311768e-01, ...,
-1.06607056e+00, -5.31036377e-01, 3.14453125e-01],
...,
[ 4.72015381e-01, 1.32940674e+00, 1.15509033e+00, ...,
-3.23403931e+00, -2.23956299e+00, -1.11035156e+00],
[ 4.14459229e-01, 1.23419189e+00, 1.07876587e+00, ...,
-3.47311401e+00, -2.56188965e+00, -1.37548828e+00],
[ 5.35278320e-02, 8.10333252e-01, 6.73461914e-01, ...,
-4.07232666e+00, -3.12890625e+00, -1.84762573e+00]]]],
dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
* month (month) int64 1 2 3 4 5 6 7 8 9 10 11 12Persist data in memory¶
If you have the available RAM for your dataset then you can persist data in memory.
This allows future computations to be much faster.
[9]:
da = da.persist()
Time Series Operations¶
Because we have a datetime index time-series operations work efficiently. Here we demo the use of xarray’s resample method:
[10]:
da.resample(time='1w').mean('time').std('time')
[10]:
<xarray.DataArray 'air' (lat: 25, lon: 53)> dask.array<_sqrt, shape=(25, 53), dtype=float32, chunksize=(25, 25), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
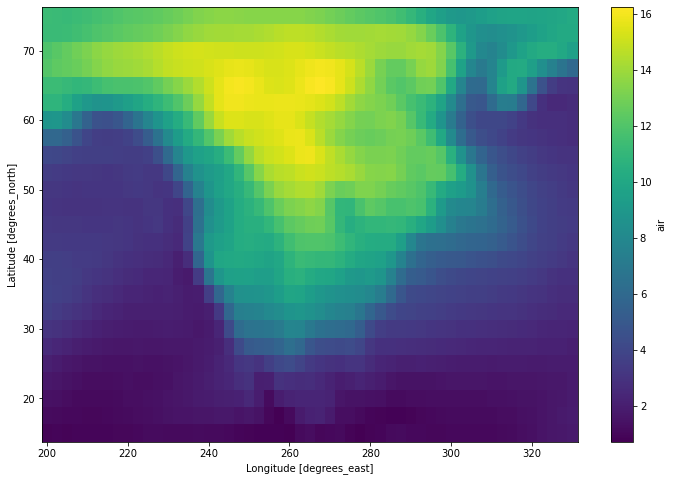
[11]:
da.resample(time='1w').mean('time').std('time').load().plot(figsize=(12, 8))
[11]:
<matplotlib.collections.QuadMesh at 0x7fc71443de80>
and rolling window operations:
[12]:
da_smooth = da.rolling(time=30).mean().persist()
da_smooth
[12]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
dask.array<truediv, shape=(2920, 25, 53), dtype=float64, chunksize=(2920, 25, 25), chunktype=numpy.ndarray>
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]Since xarray stores each of its coordinate variables in memory, slicing by label is trivial and entirely lazy.
[13]:
%time da.sel(time='2013-01-01T18:00:00')
CPU times: user 1.05 ms, sys: 2.82 ms, total: 3.87 ms
Wall time: 7.08 ms
[13]:
<xarray.DataArray 'air' (lat: 25, lon: 53)>
dask.array<getitem, shape=(25, 53), dtype=float32, chunksize=(25, 25), chunktype=numpy.ndarray>
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
time datetime64[ns] 2013-01-01T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ][14]:
%time da.sel(time='2013-01-01T18:00:00').load()
CPU times: user 23.5 ms, sys: 7.2 ms, total: 30.7 ms
Wall time: 91.1 ms
[14]:
<xarray.DataArray 'air' (lat: 25, lon: 53)>
array([[241.89 , 241.79999, 241.79999, ..., 234.39 , 235.5 ,
237.59999],
[246.29999, 245.29999, 244.2 , ..., 230.89 , 231.5 ,
234.5 ],
[256.6 , 254.7 , 252.09999, ..., 230.7 , 231.79999,
236.09999],
...,
[296.6 , 296.4 , 296. , ..., 296.5 , 295.79 ,
295.29 ],
[297. , 297.5 , 297.1 , ..., 296.79 , 296.6 ,
296.29 ],
[297.5 , 297.69998, 297.5 , ..., 297.79 , 298. ,
297.9 ]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
time datetime64[ns] 2013-01-01T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]Custom workflows and automatic parallelization¶
Almost all of xarray’s built-in operations work on Dask arrays. If you want to use a function that isn’t wrapped by xarray, one option is to extract Dask arrays from xarray objects (.data) and use Dask directly.
Another option is to use xarray’s apply_ufunc() function, which can automate embarrassingly parallel “map” type operations where a function written for processing NumPy arrays should be repeatedly applied to xarray objects containing Dask arrays. It works similarly to dask.array.map_blocks() and dask.array.blockwise(), but without requiring an intermediate layer of abstraction.
Here we show an example using NumPy operations and a fast function from bottleneck, which we use to calculate Spearman’s rank-correlation coefficient:
[15]:
import numpy as np
import xarray as xr
import bottleneck
def covariance_gufunc(x, y):
return ((x - x.mean(axis=-1, keepdims=True))
* (y - y.mean(axis=-1, keepdims=True))).mean(axis=-1)
def pearson_correlation_gufunc(x, y):
return covariance_gufunc(x, y) / (x.std(axis=-1) * y.std(axis=-1))
def spearman_correlation_gufunc(x, y):
x_ranks = bottleneck.rankdata(x, axis=-1)
y_ranks = bottleneck.rankdata(y, axis=-1)
return pearson_correlation_gufunc(x_ranks, y_ranks)
def spearman_correlation(x, y, dim):
return xr.apply_ufunc(
spearman_correlation_gufunc, x, y,
input_core_dims=[[dim], [dim]],
dask='parallelized',
output_dtypes=[float])
In the examples above, we were working with an some air temperature data. For this example, we’ll calculate the spearman correlation using the raw air temperature data with the smoothed version that we also created (da_smooth). For this, we’ll also have to rechunk the data ahead of time.
[16]:
corr = spearman_correlation(da.chunk({'time': -1}),
da_smooth.chunk({'time': -1}),
'time')
corr
[16]:
<xarray.DataArray 'air' (lat: 25, lon: 53)> dask.array<transpose, shape=(25, 53), dtype=float64, chunksize=(25, 25), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
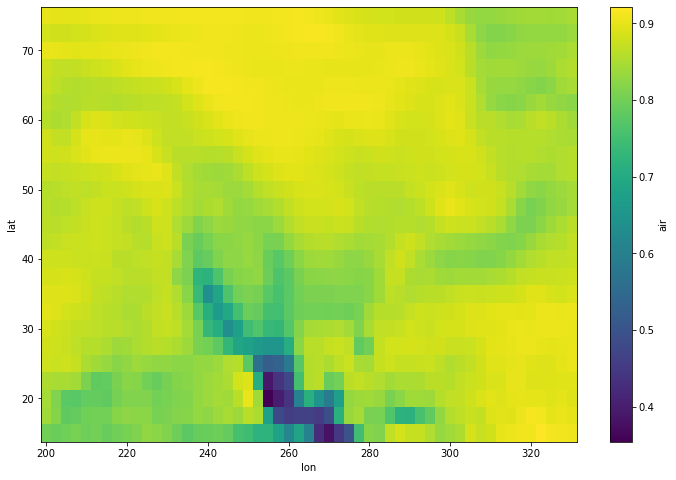
[17]:
corr.plot(figsize=(12, 8))
[17]:
<matplotlib.collections.QuadMesh at 0x7fc70cd2fdc0>