Scale XGBoost
Contents
Live Notebook
You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.
Scale XGBoost¶
Dask and XGBoost can work together to train gradient boosted trees in parallel. This notebook shows how to use Dask and XGBoost together.
XGBoost provides a powerful prediction framework, and it works well in practice. It wins Kaggle contests and is popular in industry because it has good performance and can be easily interpreted (i.e., it’s easy to find the important features from a XGBoost model).

![]()
Setup Dask¶
We setup a Dask client, which provides performance and progress metrics via the dashboard.
You can view the dashboard by clicking the link after running the cell.
[1]:
from dask.distributed import Client
client = Client(n_workers=4, threads_per_worker=1)
client
[1]:
Client
Client-ae48a4c8-0de1-11ed-a6d2-000d3a8f7959
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
d17d0b16
| Dashboard: http://127.0.0.1:8787/status | Workers: 4 |
| Total threads: 4 | Total memory: 6.78 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-63756a1e-88c9-43fb-9a77-fb66783417d3
| Comm: tcp://127.0.0.1:36303 | Workers: 4 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 4 |
| Started: Just now | Total memory: 6.78 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:36301 | Total threads: 1 |
| Dashboard: http://127.0.0.1:39597/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:46201 | |
| Local directory: /home/runner/work/dask-examples/dask-examples/machine-learning/dask-worker-space/worker-ddcw2w5v | |
Worker: 1
| Comm: tcp://127.0.0.1:40821 | Total threads: 1 |
| Dashboard: http://127.0.0.1:33095/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:36319 | |
| Local directory: /home/runner/work/dask-examples/dask-examples/machine-learning/dask-worker-space/worker-5hsjt1n7 | |
Worker: 2
| Comm: tcp://127.0.0.1:34869 | Total threads: 1 |
| Dashboard: http://127.0.0.1:44313/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:40433 | |
| Local directory: /home/runner/work/dask-examples/dask-examples/machine-learning/dask-worker-space/worker-a0hc6mn9 | |
Worker: 3
| Comm: tcp://127.0.0.1:44521 | Total threads: 1 |
| Dashboard: http://127.0.0.1:38003/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:34813 | |
| Local directory: /home/runner/work/dask-examples/dask-examples/machine-learning/dask-worker-space/worker-r6mejztr | |
Create data¶
First we create a bunch of synthetic data, with 100,000 examples and 20 features.
[2]:
from dask_ml.datasets import make_classification
X, y = make_classification(n_samples=100000, n_features=20,
chunks=1000, n_informative=4,
random_state=0)
X
/usr/share/miniconda3/envs/dask-examples/lib/python3.9/site-packages/dask/base.py:1283: UserWarning: Running on a single-machine scheduler when a distributed client is active might lead to unexpected results.
warnings.warn(
[2]:
|
Dask-XGBoost works with both arrays and dataframes. For more information on creating dask arrays and dataframes from real data, see documentation on Dask arrays or Dask dataframes.
Split data for training and testing¶
We split our dataset into training and testing data to aid evaluation by making sure we have a fair test:
[3]:
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15)
Now, let’s try to do something with this data using dask-xgboost.
Train Dask-XGBoost¶
[4]:
import dask
import xgboost
import dask_xgboost
/usr/share/miniconda3/envs/dask-examples/lib/python3.9/site-packages/xgboost/compat.py:36: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.
from pandas import MultiIndex, Int64Index
dask-xgboost is a small wrapper around xgboost. Dask sets XGBoost up, gives XGBoost data and lets XGBoost do it’s training in the background using all the workers Dask has available.
Let’s do some training:
[5]:
params = {'objective': 'binary:logistic',
'max_depth': 4, 'eta': 0.01, 'subsample': 0.5,
'min_child_weight': 0.5}
bst = dask_xgboost.train(client, params, X_train, y_train, num_boost_round=10)
Exception in thread Thread-4:
Traceback (most recent call last):
File "/usr/share/miniconda3/envs/dask-examples/lib/python3.9/threading.py", line 973, in _bootstrap_inner
self.run()
File "/usr/share/miniconda3/envs/dask-examples/lib/python3.9/threading.py", line 910, in run
self._target(*self._args, **self._kwargs)
File "/usr/share/miniconda3/envs/dask-examples/lib/python3.9/site-packages/dask_xgboost/tracker.py", line 365, in join
while self.thread.isAlive():
AttributeError: 'Thread' object has no attribute 'isAlive'
Visualize results¶
The bst object is a regular xgboost.Booster object.
[6]:
bst
[6]:
<xgboost.core.Booster at 0x7ff9c8b16610>
This means all the methods mentioned in the XGBoost documentation are available. We show two examples to expand on this, but these examples are of XGBoost instead of Dask.
Plot feature importance¶
[7]:
%matplotlib inline
import matplotlib.pyplot as plt
ax = xgboost.plot_importance(bst, height=0.8, max_num_features=9)
ax.grid(False, axis="y")
ax.set_title('Estimated feature importance')
plt.show()
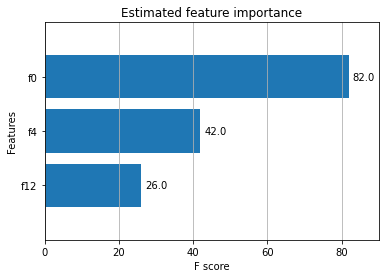
We specified that only 4 features were informative while creating our data, and only 3 features show up as important.
Plot the Receiver Operating Characteristic curve¶
We can use a fancier metric to determine how well our classifier is doing by plotting the Receiver Operating Characteristic (ROC) curve:
[8]:
y_hat = dask_xgboost.predict(client, bst, X_test).persist()
y_hat
[19:24:16] WARNING: /home/conda/feedstock_root/build_artifacts/xgboost-split_1645117766796/work/src/learner.cc:1264: Empty dataset at worker: 0
[8]:
|
[9]:
from sklearn.metrics import roc_curve
y_test, y_hat = dask.compute(y_test, y_hat)
fpr, tpr, _ = roc_curve(y_test, y_hat)
[10]:
from sklearn.metrics import auc
fig, ax = plt.subplots(figsize=(5, 5))
ax.plot(fpr, tpr, lw=3,
label='ROC Curve (area = {:.2f})'.format(auc(fpr, tpr)))
ax.plot([0, 1], [0, 1], 'k--', lw=2)
ax.set(
xlim=(0, 1),
ylim=(0, 1),
title="ROC Curve",
xlabel="False Positive Rate",
ylabel="True Positive Rate",
)
ax.legend();
plt.show()
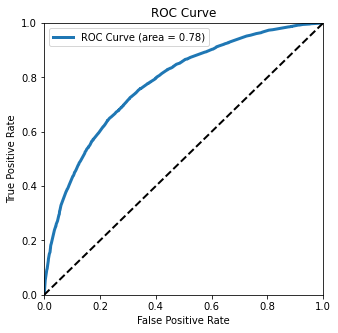
This Receiver Operating Characteristic (ROC) curve tells how well our classifier is doing. We can tell it’s doing well by how far it bends the upper-left. A perfect classifier would be in the upper-left corner, and a random classifier would follow the diagonal line.
The area under this curve is area = 0.76. This tells us the probability that our classifier will predict correctly for a randomly chosen instance.
Learn more¶
Recorded screencast stepping through the real world example above:
A blogpost on dask-xgboost http://matthewrocklin.com/blog/work/2017/03/28/dask-xgboost
XGBoost documentation: https://xgboost.readthedocs.io/en/latest/python/python_intro.html#
Dask-XGBoost documentation: http://ml.dask.org/xgboost.html