Blockwise Ensemble Methods
Contents
Live Notebook
You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.
Blockwise Ensemble Methods¶
Dask-ML provides some ensemble methods that are tailored to dask.array’s and dask.dataframe’s blocked structure. The basic idea is to fit a copy of some sub-estimator to each block (or partition) of the dask Array or DataFrame. Becuase each block fits in memory, the sub-estimator only needs to handle in-memory data structures like a NumPy array or pandas DataFrame. It also will be relatively fast, since each block
fits in memory and we won’t need to move large amounts of data between workers on a cluster. We end up with an ensemble of models: one per block in the training dataset.
At prediction time, we combine the results from all the models in the ensemble. For regression problems, this means averaging the predictions from each sub-estimator. For classification problems, each sub-estimator votes and the results are combined. See https://scikit-learn.org/stable/modules/ensemble.html#voting-classifier for details on how they can be combeind. See https://scikit-learn.org/stable/modules/ensemble.html for a general overview of why averaging ensemble methods can be useful.
It’s crucially important that the distribution of values in your dataset be relatively uniform across partitions. Otherwise the parameters learned on any given partition of the data will be poor for the dataset as a whole. This will be shown in detail later.
Let’s randomly generate an example dataset. In practice, you would load the data from storage. We’ll create a dask.array with 10 blocks.
[1]:
from distributed import Client
import dask_ml.datasets
import dask_ml.ensemble
client = Client(n_workers=4, threads_per_worker=1)
X, y = dask_ml.datasets.make_classification(n_samples=1_000_000,
n_informative=10,
shift=2, scale=2,
chunks=100_000)
X
/usr/share/miniconda3/envs/dask-examples/lib/python3.9/site-packages/dask/base.py:1283: UserWarning: Running on a single-machine scheduler when a distributed client is active might lead to unexpected results.
warnings.warn(
[1]:
|
Classification¶
The sub-estimator should be an instantiated scikit-learn-API compatible estimator (anything that implements the fit / predict API, including pipelines). It only needs to handle in-memory datasets. We’ll use sklearn.linear_model.RidgeClassifier.
To get the output shapes right, we require that you provide the classes for classification problems, either when creating the estimator or in .fit if the sub-estimator also requires the classes.
[2]:
import sklearn.linear_model
subestimator = sklearn.linear_model.RidgeClassifier(random_state=0)
clf = dask_ml.ensemble.BlockwiseVotingClassifier(
subestimator,
classes=[0, 1]
)
clf
[2]:
BlockwiseVotingClassifier(classes=[0, 1],
estimator=RidgeClassifier(random_state=0))
We can train normally. This will independently fit a clone of subestimator on each partition of X and y.
[3]:
clf.fit(X, y)
All of the fitted estimators are available at .estimators_.
[4]:
clf.estimators_
[4]:
[RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0)]
These are different estimators! They’ve been trained on separate batches of data and have learned different parameters. We can plot the difference in the learned coef_ of the first two models to visualize this.
[5]:
import matplotlib.pyplot as plt
import numpy as np
[6]:
a = clf.estimators_[0].coef_
b = clf.estimators_[1].coef_
fig, ax = plt.subplots()
ax.bar(np.arange(a.shape[1]), (a - b).ravel())
ax.set(xticks=[], xlabel="Feature", title="Difference in Learned Coefficients");
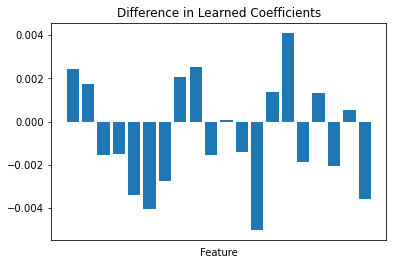
That said, the assumption backing this entire process is that the distribution of the data is relatively uniform across partitions. The parameters learned by the each member of the ensemble should be relatively similar, and so will give relatively similar predictions when applied to the same data.
When you predict, the result will have the same chunking pattern as the input array you’re predicting for (which need not match the partitioning of the training data).
[7]:
preds = clf.predict(X)
preds
[7]:
|
This generates a set of tasks that
Calls
subestimator.predict(chunk)for each subestimator (10 in our case)Concatenates those predictions together
Somehow averages the predictions to a single overall prediction
We used the default voting="hard" strategy, which means we just choose the class that had the higest number of votes. If the first two sub-estimators picked class 0 and the other eight picked class 1 for the first row, the final prediction for that row will be class 1.
[8]:
preds[:10].compute()
[8]:
array([0, 1, 0, 0, 1, 0, 1, 1, 1, 1])
With voting="soft" we have access to predict_proba, as long as the subestimator has a predict_proba method. These subestimators should be well-calibrated for the predictions to be meaningful. See probability calibration for more.
[9]:
subestimator = sklearn.linear_model.LogisticRegression(random_state=0)
clf = dask_ml.ensemble.BlockwiseVotingClassifier(
subestimator,
classes=[0, 1],
voting="soft"
)
clf.fit(X, y)
[10]:
proba = clf.predict_proba(X)
proba[:5].compute()
[10]:
array([[8.52979639e-01, 1.47020361e-01],
[1.32021045e-06, 9.99998680e-01],
[8.66086090e-01, 1.33913910e-01],
[8.78266251e-01, 1.21733749e-01],
[1.28333552e-01, 8.71666448e-01]])
The stages here are similar to the voting="hard" case. Only now instead of taking the majority vote we average the probabilities predicted by each sub-estimator.
Regression¶
Regression is quite similar. The primary difference is that there’s no voting; predictions from estimators are always reduced by averaging.
[11]:
X, y = dask_ml.datasets.make_regression(n_samples=1_000_000,
chunks=100_000,
n_features=20)
X
[11]:
|
[12]:
subestimator = sklearn.linear_model.LinearRegression()
clf = dask_ml.ensemble.BlockwiseVotingRegressor(
subestimator,
)
clf.fit(X, y)
[13]:
clf.predict(X)[:5].compute()
[13]:
array([-149.72693022, 340.45467686, -118.23129541, 327.7418488 ,
-148.9040957 ])
As usual with Dask-ML, scoring is done in parallel (and distributed on a cluster if you’re connected to one).
[14]:
clf.score(X, y)
[14]:
1.0
The dangers of non-uniformly distributed data¶
Finally, it must be re-emphasized that your data should be uniformly distributed across partitoins prior to using these ensemble methods. If it’s not, then you’re better off just sampling rows from each partition and fitting a single classifer to it. By “uniform” we don’t mean “from a uniform probabillity distribution”. Just that there shouldn’t be a clear per-partition pattern to how the data is distributed.
Let’s demonstrate that with an example. We’ll generate a dataset with a clear trend across partitions. This might represent some non-stationary time-series, though it can occur in other contexts as well (e.g. on data partitioned by geography, age, etc.)
[15]:
import dask.array as da
import dask.delayed
import sklearn.datasets
[16]:
def clone_and_shift(X, y, i):
X = X.copy()
X += i + np.random.random(X.shape)
y += 25 * (i + np.random.random(y.shape))
return X, y
[17]:
# Make a base dataset that we'll clone and shift
X, y = sklearn.datasets.make_regression(n_features=4, bias=2, random_state=0)
# Clone and shift 10 times, gradually increasing X and y for each partition
Xs, ys = zip(*[dask.delayed(clone_and_shift, nout=2)(X, y, i) for i in range(10)])
Xs = [da.from_delayed(x, shape=X.shape, dtype=X.dtype) for x in Xs]
ys = [da.from_delayed(y_, shape=y.shape, dtype=y.dtype) for y_ in ys]
X2 = da.concatenate(Xs)
y2 = da.concatenate(ys)
Let’s plot a sample of points, coloring by which partition the data came from.
[18]:
fig, ax = plt.subplots()
ax.scatter(X2[::5, 0], y2[::5], c=np.arange(0, len(X2), 5) // 100, cmap="Set1",
label="Partition")
ax.set(xlabel="Feature 0", ylabel="target", title="Non-stationary data (by partition)");
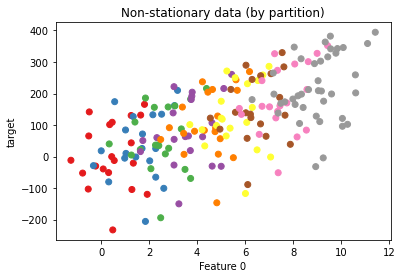
Now let’s fit two estimators:
One
BlockwiseVotingRegressoron the entire dataset (which fits aLinearRegressionon each partition)One
LinearRegressionon a sample from the entire dataset
[19]:
subestimator = sklearn.linear_model.LinearRegression()
clf = dask_ml.ensemble.BlockwiseVotingRegressor(
subestimator,
)
clf.fit(X2, y2)
[20]:
X_sampled, y_sampled = dask.compute(X2[::10], y2[::10])
subestimator.fit(X_sampled, y_sampled)
[20]:
LinearRegression()
Comparing the scores, we find that the sampled dataset performs much better, despite training on less data.
[21]:
clf.score(X2, y2)
[21]:
-11.8766583738708
[22]:
subestimator.score(X2, y2)
[22]:
0.09217254441717304
This shows that ensuring your needs to be relatively uniform across partitions. Even including the standard controls to normalize whatever underlying force is generating the non-stationary data (e.g. a time trend compontent or differencing timeseries data, dummy variables for geographic regions, etc) is not sufficient when your dataset is partioned by the non-uniform variable. You would still need to either shuffle your data prior to fitting, or just sample and fit the sub-estimator on the sub-sample that fits in memory.